PleaSQLarify: Visual Pragmatic Repair for Natural Language Database Querying
Robin Shing Moon Chan, Rita Sevastjanova, Mennatallah El-Assady
LLM users often express their intent with vague and underspecified language, leading to model uncertainty, and ultimately, brittle inference and unsatisfactory outcomes. How can a system use that uncertainty to support interactive user intent clarification?
Background: Pragmatic Repair
Natural language interfaces broaden access to complex systems, as they let users express their intent in a way that is natural to them. In the running example of database interfaces, text-to-SQL systems enable users to bypass writing complex SQL queries (e.g., SELECT product from sales) and simply retrieve data using a natural language utterance (e.g., What do we sell?
).
However, natural language does not always map deterministically and uniquely to a single SQL query. In the very basic example from above ("What do we sell?"), it is not explicitly clear whether the user would like to see all columns of the sales table, only the products column, or some type of aggregated view (e.g., counts) — these are all valid interpretations of the above utterance.
The widely used single-turn LLM interaction paradigm would sample one of these interpretations, and return a possibly unsatisfactory result to the user. We argue for a different interaction paradigm, where the system actively queries the user for clarification on unclear points. This is the idea of pragmatic repair, which we operationalize in PleaSQLarify.
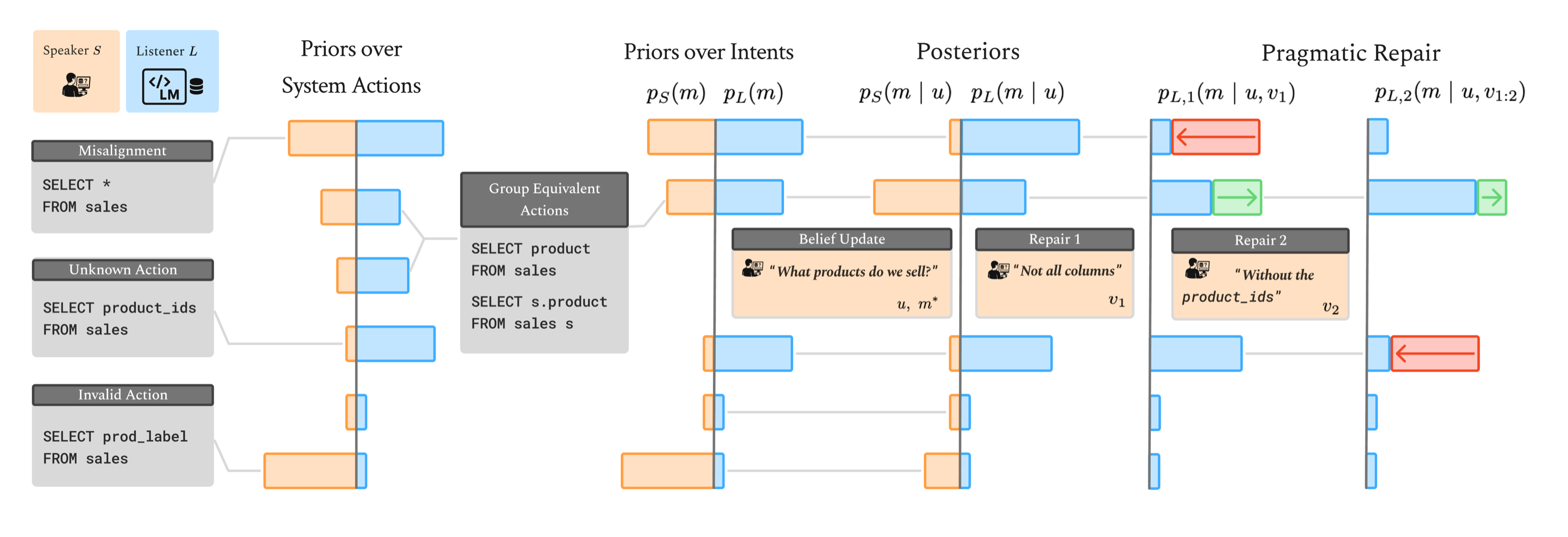
Formal figure description
In natural language interfaces, a user provides a system with an utterance , where their communicative intent is to receive their desired system outcome via a system action .2 For instance, in the text-to-SQL running example, a user may ask a system What products do we sell?
and expect a list of products from the sales table as an outcome. The system then infers a user intent given the user utterance and maps it to a suitable executable system action that ideally achieves the user's expected outcome. In the above example, this corresponds to finding the query
. We note that, generally, multiple system actions can fulfill the user intent if they are functionally equivalent, such as the target query from above and SELECT product FROM sales
, in our example. Formally, the system induces a distributionSELECT s.product FROM sales s
over executable actions given an intent . The domain of this mapping is
i.e., the set of intents for which at least one executable action is supported by the system. Thus, we can aggregate the prior probabilities of functionally equivalent programs into priors over intents and .
In natural language interfaces, a significant challenge is that the set of executable actions is often not fully known to a user (cf. the gulf of execution (Norman and Draper, 1986)). This can result in a user expressing an intent that does not map to any executable system action, or formally, . In that example, the user may ask for the "product label", even though no "prod_label" exists in the database.
More generally, there may be misalignment between the user's and the system's priors over system actions. In other words, a user may be unaware of what system actions the system considers probable and may fail to estimate how well a produced utterance distinguishes from alternative probable intents. In the same example, a system may be generally biased to show all columns, i.e., produce
. The user is unaware that this is something they need to distinguish against and assumes that their utterance SELECT * FROM salesWhat products do we sell?
yields a peaked posterior at . However, to the system, the utterance is ambiguous; its resulting posterior is high-entropy, and sampling from it leads to unexpected behavior.
Thus, communicative efficiency in natural language interfaces depends not only on the informativeness of utterances under shared priors, but also on aligning the priors themselves. This alignment can be facilitated by (a) surfacing the action space to the user, thereby reducing uncertainty about what outcomes are possible, and (b) adapting or calibrating the system's prior to better reflect the user's expectations, for instance, through clarification mechanisms.
2 The set denotes executable system actions.
Design and Algorithm
PleaSQLarify is designed around three requirements for pragmatic repair grounded in how humans interactively clarify their intent:
- As shown in the figure above, users are often unaware of the set of possible interpretations of their utterance. The system should surface the available Action Space in an incremental, human-understandable way (supported by the Action Space view).
- Assuming the user's goal is to receive a specific output (i.e., a database table), clarifications should only differentiate between functionally different programs, i.e., programs that produce different outputs (supported by the Decision Space with grouped decision variables).
- The pragmatic principle of least collaborative effort motivates minimizing the number of clarifying interactions by prioritizing asking the user informative clarifications, i.e., choosing clarifications which maximally reduce the uncertainty about the intended output (supported by the Predicted Query panel, which makes each clarification step and its effect traceable).
Based on these requirements, we propose a clarification algorithm in a five-stage loop: 1. sampling candidate SQL interpretations from the language model, 2. cluster interpretations by output similarity, 3. extracting characteristic clause-level decision variables, 4. ranking the next clarification based on expected information gain, and 5. asking the user for clarification on the most informative decision variable, and reclustering the remaining candidates.
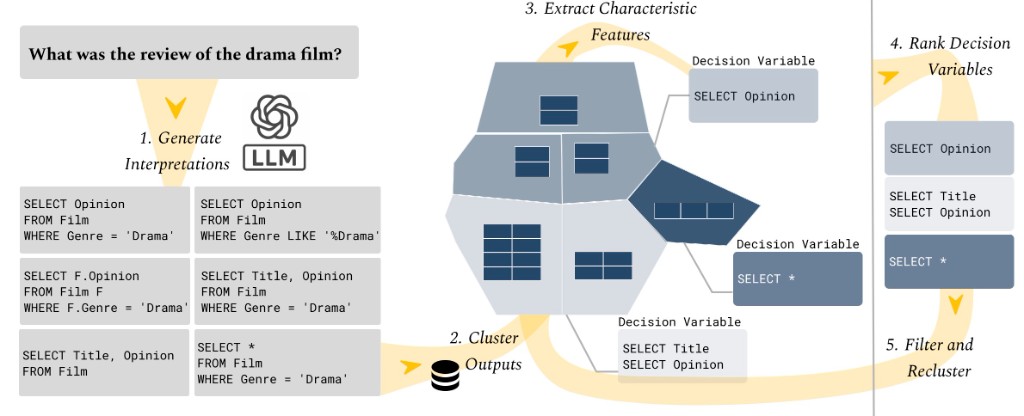
Detailed Pipeline Steps
- Generate Interpretations. Resample the language model on the utterance at high-enough temperature to obtain a diverse finite set of SQL candidates.
- Cluster Outputs. Run queries against a test database (or compare embedded result tuples) and group queries whose output behavior is similar; the interface lays this out as a Voronoi-style map so neighborhoods are visible.
- Extract Characteristic Features. Parse each query into atomic clause features; within each cluster, use statistical lift to identify characteristic clauses and bundle them into grouped decision variables users can reason about (e.g.
SELECT OpinionvsSELECT *). - Rank Decision Variables. Score grouped variables by expected information gain on the current belief over intents; surface the most informative decision variable to the user for clarification.
- Filter and Recluster. Remove candidates inconsistent with the user's reply, re-run clustering on the remaining candidates, re-extract and re-rank variables, then jump back to step 2 until one interpretation remains.
UI Components
We build an interface that supports the three requirements for pragmatic repair outlined above. It consists of three components: (1) The Action Space shows the system's candidate queries and their outputs by visualizing semantically clustered candidates in a Voronoi-style map. (2) The Decision Space lists the ranked decision variables and makes decisions more interpretable by highlighting implicitly included variables. (3) The Predicted Query panel traces the user's progress and the system's belief over the intended output at each step. We provide interactive demo widgets for the three components below.
1. Exploration: Action Space
The system generates a candidate set of SQL interpretations from the language model and lays them out as the Action Space. Each point below is one candidate query; they are embedded based on their output, and projected into 2D with UMAP. Hover or tap points to read the SQL.
2. Understanding Clusters: Decision Space
The algorithm clusters candidates by functional similarity and surfaces grouped, ranked decision variables. In the split view, hover or tap a card on the right to highlight the matching region in the Action Spaceon the left.
Decision Variables
Hover/tap to highlight candidates (red: contains clause, blue: does not).
3. Full Clarification Loop
The full clarification loop is supported by the Predicted Query panel, which traces the user's progress and the system's belief over the intended output at each step. Respond to decision-variable prompts with Yes or No to filter candidates, and step backward or forward through state when you change your mind.
User Study
We evaluated the effectiveness of the interface for (1) understanding the Action Space, (2) efficient clarification using the proposed decision variables in a user study with 12 users (P1-P12) of varying SQL expertise. As the system provides multiple ways to explore and navigate the candidate set, participants employed different approaches while solving tasks. In the figure below, we show the three distinct employed approaches for intent clarification using PleaSQLarify, which are discussed in detail below.

Usage Patterns and Insights from the Study
 Decision-Based Navigation
Decision-Based Navigation
This workflow was most common. Participants first investigated clusters in the Action Space and then used the Decision Space to filter by grouped and ranked decision variables until converging on the intended query. They mainly relied on decision variables, while selecting simple clauses in the Predicted Query panel (P1, P2, P5, P8, P12).
The Action Space and Decision Space complemented one another: the Action Spacewas rated more useful for contrasting functional output groups (M=5.67 vs. M=4.83*), whereas grouped decision variables were rated more useful for understanding those differences (M=5.33 vs. M=4.67*). Participants typically hovered over the Predicted Query panel to track their progress, using clause selection mainly at the start (e.g., fixing SELECT clauses) or near the end when few decisions remained. Although some participants noted an initial learning curve (P6, P8), many settled on this workflow because they found it most efficient for identifying semantically meaningful candidate groups (P4, P7, P10).
 Clause-Level Navigation
Clause-Level Navigation
This workflow relied heavily on atomic clause selection in the Predicted Query panel and was typically used when participants already knew the exact query they were aiming for (P5, P12). Instead of relying on decision variables, these users filtered the candidate set by selecting clauses directly and consulting tooltips.
As P4 explained, “if you know exactly what you are looking for, the tooltip and selecting clauses is useful,” while P5 described this workflow as the fastest way to reach their intended result. Many participants rated clause-level selection as more understandable than grouped decision variables due to the latter's variable prioritization, yet also reported that it required significantly more effort due to the need to scroll through long lists without prioritization (M=4.42 vs. M=3.25*). Consequently, most participants preferred the Decision Space for complex queries. For example, P4 and P11 noted that while they used clause filtering at the start, they switched to prioritized decision variables once navigation became more complex and lists of possible WHERE clauses became difficult to distinguish.
 Output-Based Navigation
Output-Based Navigation
This workflow was based on selecting promising outputs directly in the Action Space. It was mainly adopted by participants (P3, P7) who had an expectation of the output shape but were less certain about the corresponding clauses. These users relied on lasso selection to isolate clusters, compared equivalent queries, and validated results in the Predicted Output view.
Although this approach required prior knowledge of the desired output structure, it naturally marginalized over equivalent programs, which participants found harder to distinguish through clause-level navigation (M=4.67 vs. M=2.67*). This workflow became more common as query complexity increased. For instance, P2 reported that for simple column ambiguities in early tasks, clause-level filtering was sufficient, but for more complex queries, they increasingly relied on Action Space segmentation and output comparison, as clauses became too complex to interpret.
* M is the average value reported on a 7-point Likert scale.
Takeaways
The observed interaction patterns suggest principles for supporting users in clarifying underspecified intent and resolving ambiguity in natural language interfaces.
- Understanding ambiguity. In structured natural language tasks such as text-to-SQL, ambiguity is often multi-layered, with several distinct interpretations coexisting without the user's awareness. As a result, resolving such ambiguity is a decision process that unfolds over multiple interaction turns. Participants could consistently align the system with their intent when the interface surfaced this broader interpretation space, allowing them to recognize alternative meanings of their utterances and compare their outcomes.
- Clarifying pragmatically. Participants could steer the system effectively when clarification steps reduced the candidate space in ways that were both efficient and interpretable. Efficiency was supported by prioritizing decision variables, whereas interpretability emerged when decisions were contextualized: participants understood choices best when they were grounded in concrete examples, linked to their role in the query, or surfaced as implicit choices that the system made on their behalf.
- Accommodating heterogeneous repair strategies. The three workflows observed in the study highlight the complementary strengths of the Action Space,Decision Space, and Predicted Query, as well as the flexibility with which participants appropriated them. The Action Space supported broad exploration, the Decision Space provided structured and prioritized guidance, and the Predicted Query helped participants monitor convergence. Rather than enforcing a single path, users of future systems may benefit from having different strategies available, from open-ended clarification, to efficient targeting, to output-driven reasoning, depending on user goals and task complexity.
- Takeaways. Pragmatic repair extends beyond SQL. The challenge of misaligned priors and the framework of pragmatic repair apply to most natural language interfaces. By combining algorithmic selection of informative clarifications with visual techniques that reveal alternatives and make consequences observable, systems can leverage ambiguity as a resource for collaborative problem solving, supporting user control even when model interpretations misalign with user intent.
Further Reading
- D. A. Norman and S. W. Draper, editors. User Centered System Design: New Perspectives on Human-Computer Interaction. Lawrence Erlbaum Associates, Hillsdale, NJ, 1986.
- H. P. Grice. Logic and conversation. In P. Cole and J. L. Morgan, editors, Syntax and Semantics: Speech Acts, volume 3, pages 41–58. Academic Press, New York, 1975.
- H. H. Clark and D. Wilkes-Gibbs. Referring as a collaborative process. Cognition, 22(1):1–39, 1986. DOI.
- I. Saparina and M. Lapata. AMBROSIA: A benchmark for parsing ambiguous questions into database queries. In Advances in Neural Information Processing Systems (NeurIPS): Datasets and Benchmarks Track, 2024. OpenReview.
- A. Liu, Z. Wu, J. Michael, A. Suhr, P. West, A. Koller, S. Swayamdipta, N. A. Smith, and Y. Choi. We're Afraid Language Models Aren't Modeling Ambiguity. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 790–807, Singapore, 2023. ACL Anthology.
- G. Grand, V. Pepe, J. B. Tenenbaum, and J. Andreas. Shoot First, Ask Questions Later? Building Rational Agents that Explore and Act Like People. In International Conference on Learning Representations (ICLR), 2026. OpenReview.